
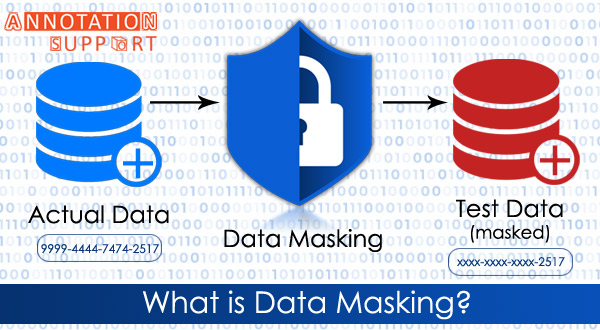
Data masking is a technique for creating a phony but realistic replica of your organization’s data. The purpose is to safeguard sensitive data while offering a functioning replacement when actual data is not required, such as user training, sales demos, or functional testing.
Data masking processes change the data’s values while keeping the same format. The goal is to create a version that cannot be reverse-engineered or deciphered.
Types of data masking:
1.Masking of Dynamic Data
Data is never kept in a secondary data store in the dev/test environment, similar to on-the-fly masking. Instead, it is streamed straight from the production system and ingested by another system in the development/test environment.
2.On-the- Masking of Fly Data
Before being saved to disc, masking data is transferred from production systems to test or development systems. Organizations that deploy software often cannot construct a backup copy of the source database and conceal it; instead, they require a method to transport data from production to various test environments constantly.
Masking delivers smaller pieces of masked data on the fly as necessary. The development/test environment saves each masked data subset for use by the non-production system. To avoid compliance and security difficulties, it is critical to apply on-the-fly masking to any feed from a production system to a development environment at the start of a development project.
3.Deterministic Data Masking:
It is the process of mapping two kinds of data to the same type of data so that another always replaces one value. For example, the name “Johnny Smith” is permanently changed with “Jimmy Jameson” in any database where it appears. This approach is helpful in many situations, but it is intrinsically less secure.
4.Masking of Static Data
Static data masking techniques might assist you in creating a clean replica of the database. The method modifies all sensitive data unless a secure version of the database can be shared. Generally, the procedure entails producing a backup copy of a production database, loading it to a different environment, removing unneeded data, and masking it while it is in stasis. After that, the disguised copy may be pushed to the desired place.
Techniques of data masking:
According to the GDPR, pseudonymization is any approach that assures data cannot be used for personal identity. It necessitates the elimination of direct identifiers and, preferably, the avoidance of multiple identifiers that, when combined, can identify a person.
1.Data Reorganization: Data values are exchanged inside the same dataset, similar to replacement. A random sequence is used to reorganize data in each column, such as swapping between real customer names across several client records. The result set appears to be actual data, but it does not provide an accurate data set for each individual or data item.
2.Variation in Value: A function replaces the original data values, such as the difference between the series’s lowest and most incredible value.
Taking a Break: When an unauthorized user views data, it seems missing or “null.” As a result, the data is less valuable for development and testing.
3.Encryption of data: This is the most secure type of data masking, but it is also the most difficult to deploy since it necessitates continuing data encryption technology and systems to store and exchange encryption keys.
Conclusion
Data masking is required in many regulated businesses, where personally identifiable information must be shielded from overexposure. By masking data, the business may make it available to test teams or database administrators as needed without jeopardizing data security or violating compliance. The main advantage is that the security risk is lessened.
Interested to get high quality and data secured annotation services, contact us immediately through filling the form at https://www.annotationsupport.com/contactus.php