Annotation Services
- Bounding Box
- Polygon
- 3D LiDAR
- Geospatial
- Line Annotation
- Autonomous Vehicle
- Image Annotation
- Image Masking
- Cuboid Annotation
- Semantic Segmentation
- Video Annotation
- Key Point Annotation
- Text Annotation
- Audio Annotation
- Instance Segmentation
- Data labelling Services
- Image Classification Services
- Image Recognition Services
- Image Processing Services
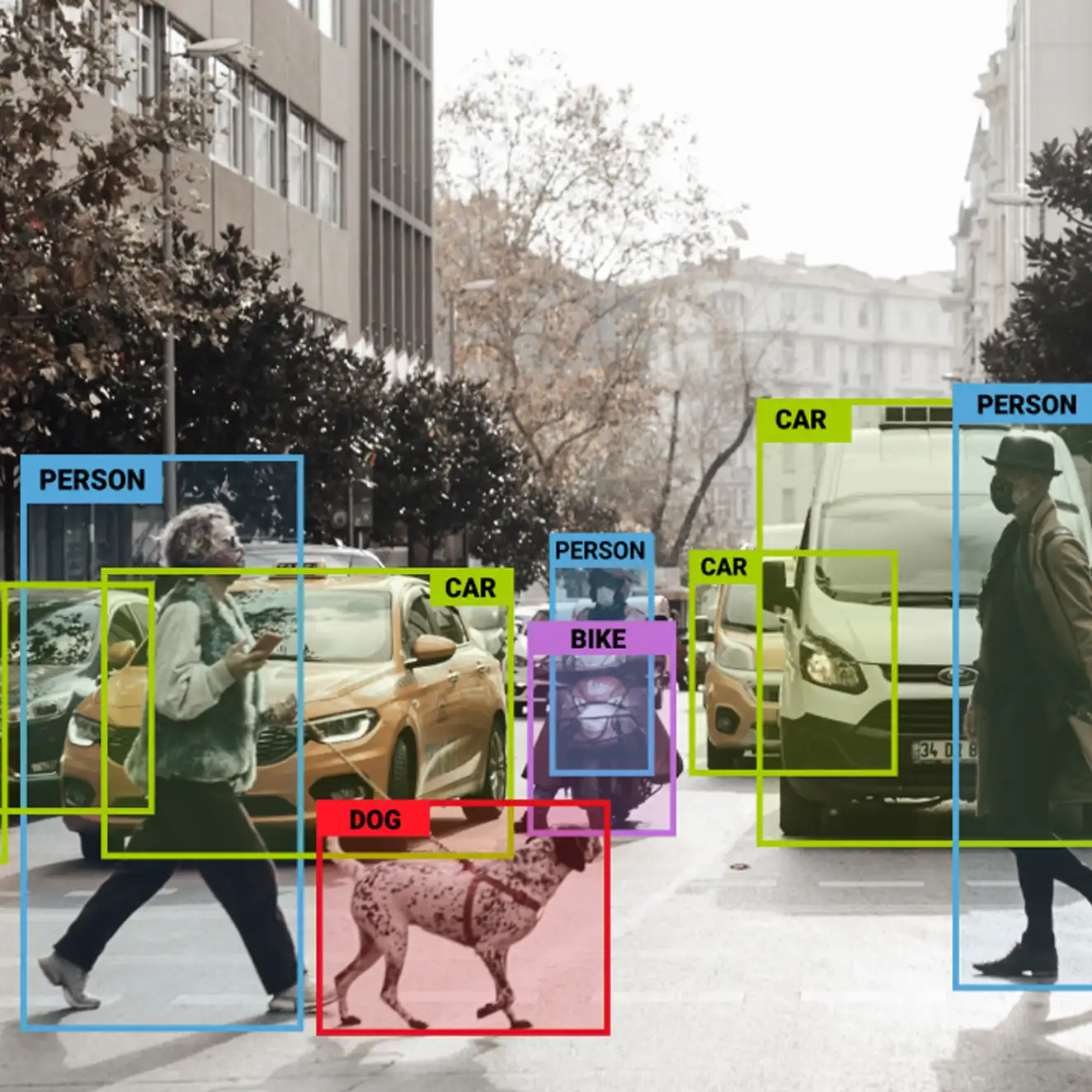
Data Labelling Services
Data labelling and annotation services that are crucial for training machine learning (ML). These services are basically about adding metadata to the data so that the ML algorithms can find correlations and make correct predictions. This has been due to the increased uptake of AI across sectors such as healthcare, autonomous driving, natural language processing among others making the need for quality labelled datasets to be high.
Benefits and Challenges of Data Labelling Outsourcing:
Benefits of Data Labelling
Enables Supervised Learning: Models of supervised ML heavily depend on labelled data sets. Clean data helps models understand the correct examples they are given and thus perform better on new sets of data.
Improves Model Accuracy: High quality of labelled data that affects the effectiveness of AI models. It is very important to have the input and output variables clearly labelled, and more importantly, described in the same manner, to yield better results from the models.
Supports Diverse AI Applications: High quality of labelled data that affects the effectiveness of AI models. It is very important to have the input and output variables clearly labelled, and more importantly, described in the same manner, to yield better results from the models.
Challenges faced by Data labelling company:
Time-Consuming:
A lot of time is usually spent in the process of data labelling especially when more complex tasks such as image segmentation or 3D data annotation is to be done. For example, when it comes to the process of labelling a video frame by frame, or identifying objects in dense LiDAR point cloud, the process can be quite time consuming.
High Cost:
Because data labelling is a manual process, it is costly, and the cost increases for high-quality data labelling. While crowdsourcing cuts costs, it may sometimes need a few more levels of quality assurance.
Quality and Consistency Issues:
Misleading or incorrect labels are known to reduce the effectiveness of a model. Some errors are possible due to human annotators, misunderstanding guidelines, or even providing inconsistent labels to the data. Such quality control measures as consensus reviews are necessary but they take time and are expensive.
While data labelling is a crucial part of building effective machine learning models, it comes with significant challenges like cost, time, and quality control. However, with advances techniques used by Annotation Support team such as automation, the availability of managed services and strategies to ensure accuracy, the labelling process was optimized to improve the performance and generalization of AI models.
